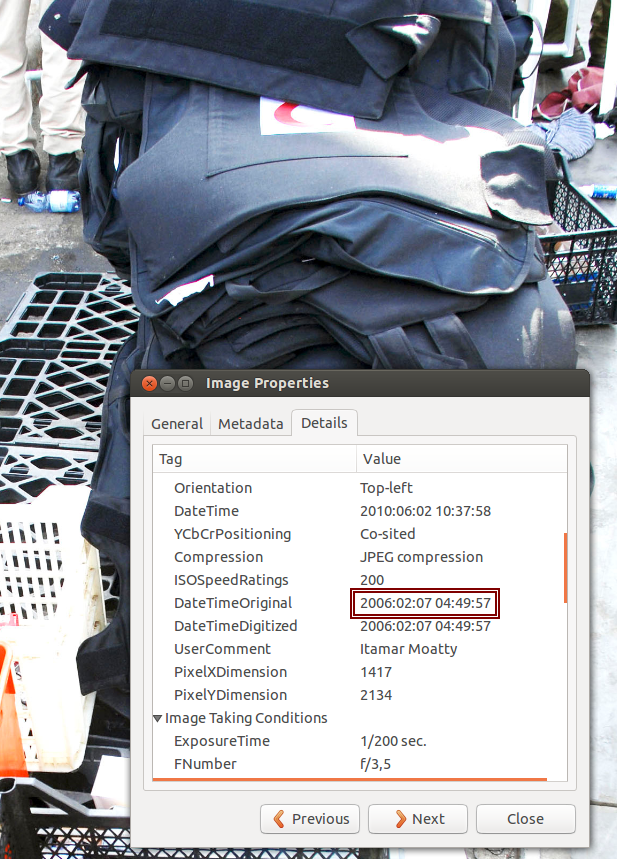
 När Israel bordade Ship to Gaza-båten 2010, publicerade det israeliska utrikesdepartement på sitt Flickrkonto bilder de tagit på olika vapen ombord: Skyddsvästar, köksknivar, yxor, nattkikare och en mattkniv (eller något snarlikt). Snart upptäckte Internet att något stod fel till med datumen på bilderna. De flesta kameror lagrar en massa metadata i bilderna de tar: Kameranamn, datum, exponeringstid, etc, etc. Många av de här bilderna hade fotodatum flera år tillbaka i tiden. En bild så tidigt som 2003. Det blev en mindre bloggbävning; Hade den israeliska militären fejkat bilderna? Det kommer vi förstås aldrig att säkert veta, men svaret är sannolikt nej. En av bilderna var visserligen tidsstämplad februari 2006, men det betyder bara att kamerans klocka visade 2006. Kanske hade den nollställts sist batteriet tog slut? Kanske var den aldrig ställd? På 2006-bilden framgår även kameramodell av metadatan: Nikon D2Xs. Den modellen fanns inte ens på marknaden då. Den släpptes först senare samma år. Datumet saknade alltså helt bevisvärde.
När Israel bordade Ship to Gaza-båten 2010, publicerade det israeliska utrikesdepartement på sitt Flickrkonto bilder de tagit på olika vapen ombord: Skyddsvästar, köksknivar, yxor, nattkikare och en mattkniv (eller något snarlikt). Snart upptäckte Internet att något stod fel till med datumen på bilderna. De flesta kameror lagrar en massa metadata i bilderna de tar: Kameranamn, datum, exponeringstid, etc, etc. Många av de här bilderna hade fotodatum flera år tillbaka i tiden. En bild så tidigt som 2003. Det blev en mindre bloggbävning; Hade den israeliska militären fejkat bilderna? Det kommer vi förstås aldrig att säkert veta, men svaret är sannolikt nej. En av bilderna var visserligen tidsstämplad februari 2006, men det betyder bara att kamerans klocka visade 2006. Kanske hade den nollställts sist batteriet tog slut? Kanske var den aldrig ställd? På 2006-bilden framgår även kameramodell av metadatan: Nikon D2Xs. Den modellen fanns inte ens på marknaden då. Den släpptes först senare samma år. Datumet saknade alltså helt bevisvärde.
Flickr-albumet blev ingen PR-succé för Israel, men det berodde nog mer på att de flesta föremål där är sådana man kunde vänta sig att hitta på en båt, än på några tveksamheter kring bildernas metadata.
Att fiska information i metadata är något av det mest frustrerande en webbresearcher kan ägna sig åt, och Ship to Gaza-exemplet är ett bra exempel på varför. Det är en potentiell guldgruva: Där kan finnas exakt hur mycket spännande information som helst. Samtidigt är det 499 gånger av 500 inte värt tiden. Oftast finns där inget. Och när det finns så är det svårt eller omöjligt att veta hur tillförlitlig datan är.
Förra året byggde vi på datajournalist-nätverket J++ ett verktyg för att med en knapptryckning samla metadata från alla dokument på sajt. Tanken är att att göra det så enkelt att det är värt jobbet, även om du bara hittar den där superintressanta informationen en gång av 500. Länkar och mer information om verktyget (som fortfarande är i något slags tidigt beta-stadium) finns längst ner i det här inlägget. Innan vi kommer dit, ska vi gå igenom några vanliga, och användbara[1] typer av metadata, med hjälp av toaletter.
Toalettbilderna
Samtidigt som de första journalisterna anlände till sina hotell i Sotji inför OS, började nätet (och klickjagande mediesajter) bubbla av bilder på halvfärdiga hotellrum, sprutmålade gräsmattor och, just det, toaletter. Twitterkontot @SochiProblems blev något slags sambandscentral, som med mer skadeglädje än källkritik spred vidare bilder på temat.
https://twitter.com/SochiProblems/statuses/431259988581810176
Bild-metadata kallas ofta slarvigt för Exif-data, men Exif är i själva verket bara en av många typer av metadata som kan finnas i (framför allt jpeg-) bilder. Förutom datum och kamerainformation kan det finnas geografiska koordinater (från till exempel en mobiltelefon), användarnamn och mjukvaruinformation från bildredigeringsprogram, och mycket, mycket annat. Problemet är att de flesta bilder du stöter på på nätet är strippade på metadata. Det gäller till exempel alla bilder som laddats upp på Facebook eller Twitter.[2] Då vill du leta efter originalbilden för att hitta så många detaljer som möjligt.
En bra start är att bild-Googla (och/eller söka på Tineye), och då efter de största storlekarna. Välj ”more sizes” och ”large” för att se just de största. De flesta beskurna bilder kommer ju att vara mindre än orginalet. Här är en bildgoogling på en annan av alla tio- eller hundratals toalettbilder som påstods komma från OS-byn i Sotji.
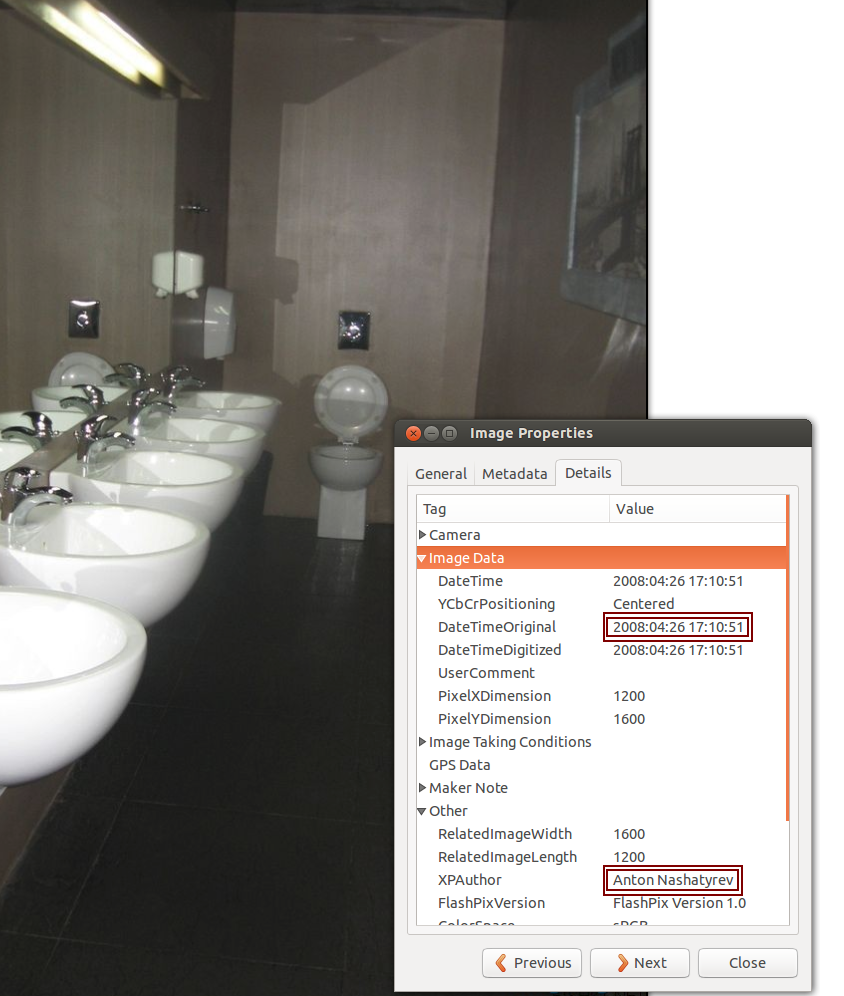 Den första (största) bilden leder oss till en ungersk blogg som publicerar humoristiska (det är nog avsikten) bilder och bildmontage. Ladda ner bilden, och öppna den i ditt favoritprogram. Plocka fram metadatan (<alt>-<enter> i standardbildprogrammet på de flesta Linux-datorer). Om den stämmer är bilden tagen 2008. Här finns också ett namn,
Den första (största) bilden leder oss till en ungersk blogg som publicerar humoristiska (det är nog avsikten) bilder och bildmontage. Ladda ner bilden, och öppna den i ditt favoritprogram. Plocka fram metadatan (<alt>-<enter> i standardbildprogrammet på de flesta Linux-datorer). Om den stämmer är bilden tagen 2008. Här finns också ett namn, Anton Nashatyrev, att leta efter, om vi vill gå vidare. Nu kan vi nöja oss med att den varit publicerad på nätet långt före OS i Sotji.
Låt oss göra samma sak med bilden med det gula vattnet, som ligger inbäddad lite längre upp. Om du söker efter den största versionen av den bilden på Googles bildsök blir du besviken: Det är inte alls originalet. Bildkvaliteten avslöjar att det här är en bild som förstorats upp över sin originalstorlek. Originalet hittar vi längre ner på listan, här. Och även här finns ett datum i metadatan. Oktober 2013 (vilket ser ut att vara datumet då bilden redigerats i något bildbehandlingsprogram).
{kind=link}
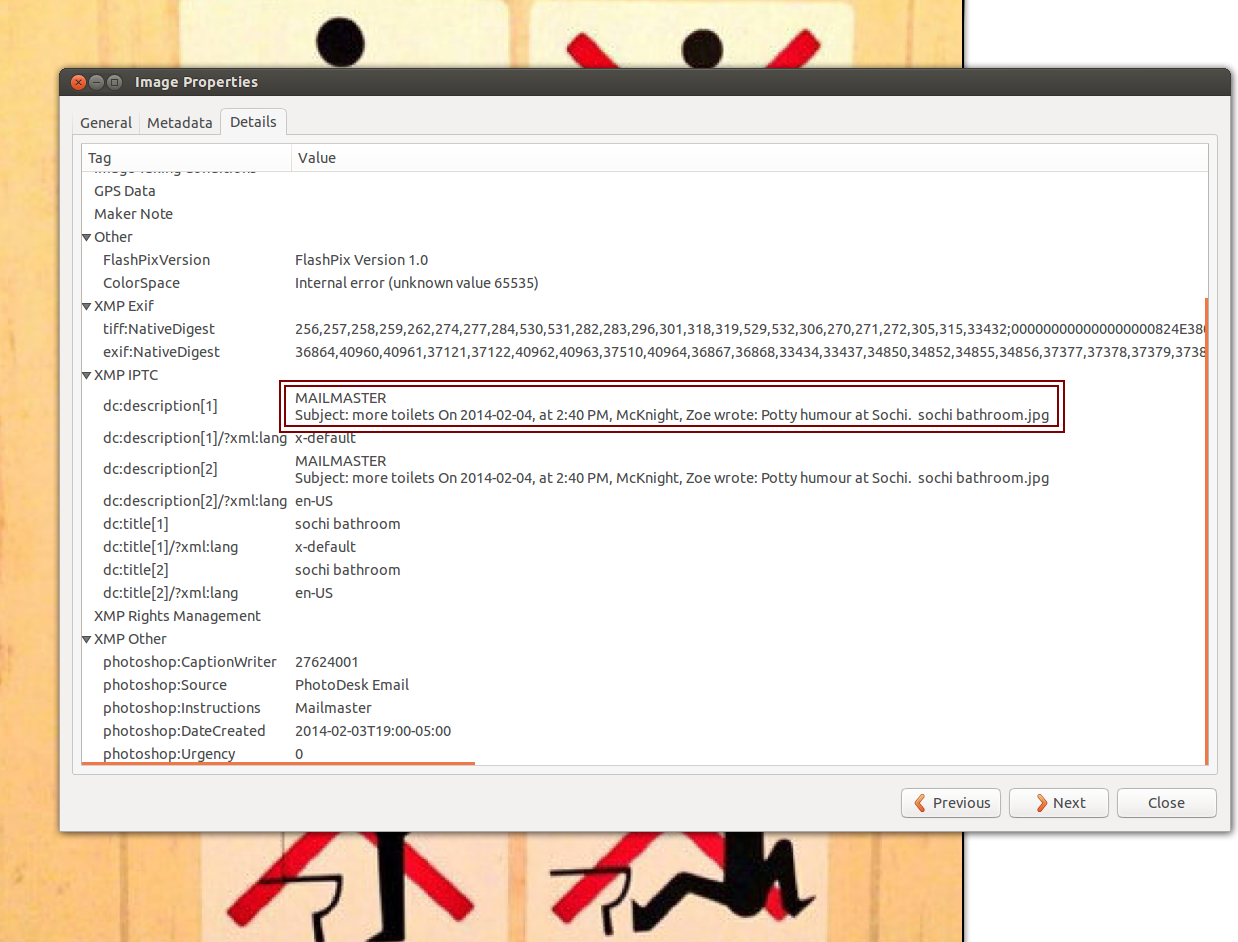
Och i den här bilden (som faktiskt verkar vara från Sotji[3]) ser vi vilken reporter på The Star som har mejlat bilden (till sig själv, från Instagramklienten PhotoDesk, skulle jag gissa).
{kind=link}
Så går det att fortsätta länge med alla tokroliga Sotji-foton. Ofta finns det ännu enklare sätt att upptäcka att en del av dem publicerats förut. Till exempel genom att kolla datumen på andra Googleträffar. Eller, som här, genom sunt förnuft och något slags rimlighetsbedömning [original].
Pdf-filer
Så gott som alla PDF-visningsprogram låter dig se tillgänglig metadata. I Evince, som jag använder är kort-kommandot på Linux <alt>-<enter>. Leta i menyerna i ditt program så hittar du det snart (tipsa gärna i kommentarsfältet om kortkommandon i de vanligaste Windows- och Macprogrammen!). Några fält är uppenbart intressanta: Author kan innehålla användarnamnet på den som skapade dokumentet. En del PDF-skapare lägger till det automatiskt, om inte användaren väljer bort det, något som många verkar omedvetna om. I PDF:er som skapats i tjänsten av personer på olika företag, finns ofta användarens inloggningsnamn på datorn kvar där. Mer ofta än sällan består inloggningsnamnet av de första bokstäverna i förnamnet och de första bokstäverna i efternamnet. Även mer teknisk data kan vara intressant. Producer och creator innehåller namn, och ibland exakt version, på mjukvaran som använts för att skapa dokumentet. Det kan hjälpa oss att stärka eller försvaga misstankar om att två dokument kommer från samma ställe. På samma sätt kan vi använda uppgifterna om vilka typsnitt som bäddats in. Både typsnitt och mjukvara ger också en hint om vilket operativsstem användaren har använt, något vi i sin tur kan stämma av mot vad vi vet om ett företag eller en myndighet. Och så en brasklapp: All den här informationen går att förfalska, för den som vill och har kunskapen.
Kontorssviter (Word, Excel, LibreOffice)
Alla kontorsprogram (Microsoft Word och Excel, LibreOffice Writer och Calc, etc, etc) bäddar ofta in en mängd information som skribenten inte alltid är medveten om. Exempelvis kan där finnas användarnamn.
DOCX
Nyare Microsoft Office-versioner använder ett dokumentformat som kallas Office Open XML. De har oftast[4] filändelsen docx. Sådana filer är i själva verket packade XML-filer. XML eller ett trevligt format, eftersom det, även om det är tänkt att läsas av maskiner, är ganska begripligt också för människor. Du behöver att arkivprogram (ett sådant som du använder för att packa upp och packa ner zip-filer, till exempel) för att packa upp docx-filen, som i själva verket är ett zip-arkiv. Då får du en katalog med ett antal underkataloger, med flera xml-filer i. I xml-filerna lagras inte bara själva innehållet, texten, utan också all metadata, och dessutom en mängd mer eller mindre obskyra inställningar, vilket i sig kan vara intressant. Språkinställningarna (det brukar finnas tre, en för språk som skrivs från vänster till höger, en för språk som skrivs från höger till vänster, och en för ostasiatiska språk) kan till exempel avslöja vilka språk användaren oftast skriver på, vilket kan tänkas vara en användbar pusselbit för att ringa in upphovsmannen till ett dokument.
Janus – extrahera metadata automatiskt
Så hur kommer vi runt det första problemet, att metadata, trots att det är en sådant potentiell guldgruva, så sällan är värt besväret? Verktyget Janus från datajournalistnätverket J++, är ett svar på frågan. Tanken är att om det bara är en knapptryckning bort att samla in metadata från ett stort antal dokument, så kan det bli en standardkoll för den som undersöker en sajt, lika självklart som att slå upp vem som registrerat domänen (för det gör du väl?). Eller en hjälp för den som vill slippa trampa i källkritikklaveret för ofta.
Janus är knappt ens en beta. Det fungerar visserligen oftast som det ska, men det kräver en del teknisk kunskap att installera och kunna köra det. Om ord som node.js, git och API-nyckel känns bekanta och ofarliga, så bör du inte ha några problem att följa de summariska instruktionerna på sajten. Ta hjälp av någon annars! Programmet använder sökmotorn Bings API för att hitta alla PDF:er på en sajt, ladda ner dem, och extrahera alla metadata. För den som är programmeringskunnig skulle det gå relativt enkelt att bygga på en modul för att hämta jpeg-bilder, Worddoument (det finns redan färdiga node.js-bibliotek för själva metadatautvinningen) och annat. Och hör gärna av dig om du testar!
bildnamn.psd, efter att ha redigerats i Photoshop. På Windowsdatorer kan du behöva döpa om filen för att kunna öppna dem. Om du använder Linux kan du alltid skriva file FILNAMN vid kommandotolken, eller i de allra flesta Linuxversioner högerklicka och välja ”egenskaper”/”properties” eller liknande, för att ta reda på vilken filtyp en fil har.
3 reaktioner till “Fiska med metadata”