Vi är många journalister som kan vittna om seminariets betydelse för vår egen yrkesmässiga utveckling. Att det dessutom är ett trevligt tillfälle att knyta kontakter med kollegor från alla håll i landet, gör det inte sämre.
Bland årets föreläsare finns internationella stjärnor som Paul Myers och Susanne Craig och inhemska storheter som Malin Crona, Kerstin Weigl, Nils Hanson och Fredrik Laurin.
Dessutom får man höra metodbeskrivningar av alla de 26 gräv som tävlar om årets guldspadar.
Själv kommer jag att avslöja alla detaljer om den så kallade strumpskandalen, samt tillsammans med Marja Grill försöka ta något slags rekord genom att gå igenom 60 idéer på 60 minuter.
En av våra favoritkollegor i genren journalistikbloggare är Ulrika Hedman, som forskar på JMG om journalisters användning av sociala medier. Hon har på sin utmärkta blogg Eftertänkt uppmärksammat en norgehistoria som inte är särskilt rolig – men extremt intressant och lärorik. Det handlar om en teknik som i Sverige bland annat använts av nätektiven Peter Forsman när han hjälpte Plus att lokalisera ett lotteriföretag. Det norska fallet är lite tvärtom eller hur man ska uttrycka det…och Ulrikas post är så intressant att vi med glädje återpublicerar den här!
Skärmdump från loggen på Blasze. Loggen visar de ip-adresser som klickat på en viss länk som försetts med en spårare. Via en ip-tjänst är det lätt att ta reda på var ip-adresserna finns, eller triangulera med andra loggar.
Om det lämpliga i att som journalist spy galla över kollegor, konkurrenter och källor i skydd av en pseudonym kan man tycka mycket, och det gör jag också. Det är naturligtvis inte bra och skadar trovärdigheten för inte bara den enskilda journalisten utan för hela journalistiken. Och förr eller senare kommer man att bli avslöjad, hur väl man än försöker gömma sig – tro inte annat. Med de orden lämnar jag just den aspekten på det här avslöjandet, för att i stället titta närmare på hur själva avslöjandet gick till.
För att ringa in och avslöja personen bakom det anonyma kontot användes ett verkligt klickbete. Med klickbete menar jag här inte det vanliga klickbetet i form av en känslovinklad rubrik som ska locka publiken att klicka sig vidare till en text. Utan jag menar klickbete som i honeytrap, alltså en fälla.
Så här funkar det: Med en tjänst Blasze IP logger skapar du en särskild url till valfri länk. Med andra ord tar du en länk och klistrar in i sökrutan, och ut kommer en länk som ser ut som en förkortad länk men som dessutom innehåller en tracker, alltså en spårare. Du delar sedan den särskilda Blazse-länken, och alla som klickar på den loggas sedan med bland annat ip-nummer (se skärmdumpen). Vill du maskera ditt klickbete använder du sedan en ”vanlig” länkförkortare, som till exempel bit.ly – för vem misstänker väl en bit.ly-länk?
Sedan är det bara att triangulera. Journalisterna i det norska avslöjandet skickade en länk via Twitters direktmeddelanden till det anonyma kontot, och kunde konstatera att personen bakom det befann sig på samma plats som en av personerna på listan över misstänkta. Ett alternativ är att jämföra ip-nummer. Det gäller bara att ha lite koll på vem du delar länken med.
Den här metoden är naturligtvis väldigt användbar för journalister i det normala nyhetsarbetet, kanske framför allt för att avslöja anonyma konton på nätet – det kan röra sig om näthatare, personer som hotar, politiker som sprider främlingsfientliga åsikter eller foliehatterier när de tror att ingen ser.
Men den kan också användas för att avslöja journalister som använder sig av anonyma nätidentiteter för att kunna researcha och röra sig i miljöer där journalister normalt sett inte är välkomna. Eller som använder en anonym nätidentitet för att kommunicera med en källa för att inte riskera att avslöja källans identitet.
Så vad kan du göra som journalist? Även om du inte har ett behov av att vara anonym kanske du inte vill avslöja var du befinner sig vid ett givet tillfälle? Visst, ”klicka aldrig någonsin på en länk” kanske låter som ett gott råd, men det fungerar naturligtvis inte i det dagliga arbetet. Följande tips kan användas var för sig eller tillsammans, beroende på vilken säkerhetsnivå du anser nödvändig:
Använd Tor och Tails för att skydda din anonymitet på nätet.
Använd vpn! (Själv använder jag just nu en vpn-tjänst som skickar min mobiltrafik över en server i Tyskland, det syns på den andra loggningen i bilden ovan.)
Koppla aldrig upp dig på ”gratis” eller ”fri” wifi. (Aldrig någonsin, de läcker som ett såll.) Om du ändå måste använda ett sådant nät, använd vpn!
Använd en särskild telefon med kontantkort och kontant surfpott för de gånger du måste röra dig anonymt på nätet. Använd också den telefonens nät för att koppla upp dig mot nätet från andra enheter. Använd aldrig den telefonen som ”dig själv” för att undvika den typen av ip-triangulering jag beskriver ovan.
Läs iss-guiden om digitalt källskydd för journalister av Sus Andersson, Fredrik Laurin, Petra Jankov Picha och Anders Thoresson. Där finns många andra viktiga råd om hur du som journalist skyddar både dig själv och dina källor.
Ulrika Hedman
Fotnot: Det finns många andra tjänster än Blasze och bit.ly som gör samma saker. Det finns också en rad tjänster som visar var en ip-adress finns, till exempel ipnr.se.
Dessutom har jag hört lovord hagla över både Linda Kakulis och Malin Cronas föreläsningar, om personkartläggningar respektive fakturagranskningar. Och de är inte de enda som fått beröm…
Kvällarna är helt enkelt räddade ett bra tag framöver. Nu får tv-serierna vänta ett tag till förmån för supergranskningskompetensökningsstreaming-underhållning från Göteborg.
Ett nytt år nalkas, och det har blivit dags att summera 2015. Vi gör det genom att tipsa om några poster du möjligen kan ha missat under det gångna året.
Och för den handlings-inspirerade har vi sedan i en liten miniserie (del 1 och del 2) listat tio typer av dokument som vi kanske inte alltid tänkt på att begära ut.
I kategorin under granskningen (åtminstone vad gäller avslöjandeambitioner) finns det klassiska tredagarsjobbet, som vi beskrev hur man enklast lägger upp för att nå ett lyckat reslutat.
Till kategorin superkonkreta tips hör detta om metoden att söka bara under en viss domän eller webbadress, för att (till exempel) hitta bloggformuleringen som den nya partiledaren vill glömma.
I sin blogg på Dagens Nyheters webbplats skriver statsvetardoktoranden Anders Sundell bland annat om sambandet mellan benägenheten att rösta på Sverigedemokraterna och Feministiskt initiativ å ena sidan, och utbildningsnivån å den andra.
Jag blev nyfiken på hur jag skulle kunna göra samma analys bara för Skåne, där jag arbetar. Och samtidigt – kolla hur sambandet ser ut när det gäller exempelvis andra partier.
Tabellen längst ner på sidan är enkel att skrapa från sidan, exempelvis med hjälp av Chrome-tillägget Scraper. Sedan man installerat det, markerar man bara en bit av tabellen, högerklickar och väljer ”Scrape similar”. Därefter dyker den upp som en tabell som är enkel att exportera vidare till Google Drive.
En bra sak här är att kommunerna redan står i bokstavsordning. Det kan vi ha glädje av senare.
Därifrån valde jag att exportera det vidare till Excel.
En färdig tabell över utbildningsnivån i landet från 2013 finns nedbruten på kommunnivå på Statistiska centralbyråns sajt. Det är den tredje uppifrån på den här sidan.
Jag gick vidare med att skapa ett nytt kalkylblad i Excel. Jag plockade ut Skånekommunerna ur SCB-statistiken (tips: de står efter varandra!) och la in dem. Genom att sortera dem i bokstavsordning är det sedan enkelt att bara ställa upp valstatistiken intill.
I mitt Exceldokument har jag då kommunnamnen i första kolumnen, utbildningsnivån i den andra och därefter valresultaten i procent. Kolumnen med de absoluta siffrorna har jag plockat bort.
Däremot såg jag ingen anledning att inte behålla kolumnerna ”ÖVR” (övriga), ”BLANK” (blankröster), ”OG” (ogiltiga) samt ”VDT” (valdeltagande). De stör ju ingen.
När vi nu skaffat oss lite ordning och reda på det underlag vi behöver, är det dags att begripliggöra siffrorna. För att enkelt kunna publicera diagrammet på webben kan man exempelvis använda tjänsten Infogram.
Efter att ha skapat ett konto väljer vi Create, därefter Charts och slutligen Scatter. Klicka på Add chart. Dubbelklicka på diagrammet för att få fram tabellen. Ta bort exemplet, och lägg därefter in kommunnamnen i första kolumnen, utbildningsnivån i andra kolumnen och valresultatet för Sverigedemokraterna i den tredje.
Ändra inställningarna genom att klicka på fliken Settings. Ange till exempel ”X Axis label” till ”Andel med lång högskoleutbildning” och ”Y Axis label” till ”Andel som röstade på Sverigedemokraterna”. Klicka på Done.
Spännande! Resultatet i Skåne liknar ju det som den bloggande statsvetaren fick fram för riket.
Vi snyggar till vårt diagram lite till.
Dubbelklicka på rubriken och ange ”Andel sverigedemokrater vs utbildningsnivå i Skåne”. Dubbelklicka på textrutan under själva diagrammet och ange ”Källa utbildningsnivå: SCB. Källa valresultat: Valmyndigheten.” Klart!
Klicka på knappen Share och välj sedan det alternativ som passar dig bäst. För att bädda in på bloggen väljer jag bland alternativen längst ner.
Finns det något annat intressant samband? Det visade sig direkt efter valet att universitetsstaden Lund stack ut åt andra hållet – ett ovanligt svalt intresse för Sverigedemokraterna i kombination med en ovanligt hög utbildningsnivå. Kan valdeltagande över lag har något med utbildningsnivå att göra? (Ja!) Låt oss kontrollera – vi har ju den kolumnen. Gör alltså som tidigare i Infogram, men lägg in kolumnen ”VDT” längst till höger i stället för SD:s valresultat. Uppdatera axlar, rubrik och informationsruta i enlighet med det.
Nu frågar sig förstås den nyfikne hur sambandet mellan Fi-röstande och utbildningsnivå ser ut i Skåne. Enligt Anders Sundell var det ju påtagligt i riket. Vi går vidare i Infogram med rösterna på Feministiskt initiativ.
Här är det inte alls lika tydligt att utbildningsnivå och en lagd röst på Feministiskt initiativ hänger ihop. I stället verkar röstandet vara mer utspritt i väljarkåren. Jag konstaterar bara det. Analyserna har vi ju statsvetare till. Folkpartiet och Miljöpartiet då? Hur ser det ut?
Nu uppstår förstås frågan hur jag har kunnat gissa så bra. Det verkar ju som om det ofta blir ett ganska tydligt samband. Hur har jag kunnat chansa så bra?
Det finns ett statistiskt mått på hur starka den här typen av samband är – alltså hur väl de olika variablerna korrelerar med varandra. Det är förstås mycket lätt att beräkna det här måttet i Excel.
Korrelation i Excel
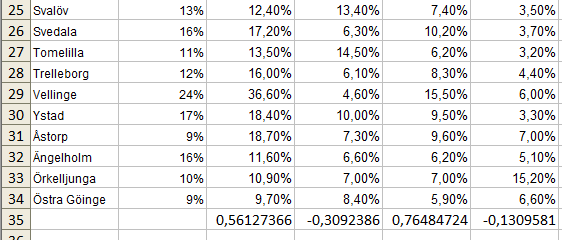
På raden längst ner i mitt kalkylblad har jag lagt in formeln för att beräkna korrelationen mellan valresultaten i den aktuella kolumnen och andelarna med högutbildade. Det är ganska enkelt att göra det med hjälp av funktionen KORREL().
I det aktuella fallet kan det till exempel vara =KORREL($B2:$B34;C2:C34). Första argumentet är den ena kolumnen, och andra argumentet är den andra. För att jag ska kunna kopiera formeln till höger men alltid jämföra valresultatet med utbildningsnivån och inte med ett annat parti, så har jag satt dollartecken framför kolumnbokstäverna i första argumentet – det fryser dem.
Man får ett mått mellan –1 och +1. Ju närmare –1 respektive +1 man hamnar, desto starkare är korrelationen. Tal närmare 0 visar att variablerna inte samvarierar i lika stor utsträckning.
Första värdet på rad 35 handlar om Moderaterna och det tredje om Folkpartiet. Med hjälp av de här siffrorna kan vi alltså i någon mån i förband lista ut vilka korrelationer det är värt att göra ett diagram på.
Korrelationen mellan SD-röster och utbildningsnivå är nästan starkast, –0,84. Men det finns en som är lika stark, fast positiv, +0,84. Det är den mellan utbildningsnivå och valdeltagande över huvud taget.
Det har blivit dags för ett nytt avsnitt av Scrapingskolan. I denna sjunde del går vi igenom hur man använder gratisverktyget OutWit Hub för att scrapa sajter på innehåll.
Finessen är att programmet kan använda sig av de next-länkar som finns på vissa sidor då ett långt sökresultat presenteras uppdelat på ett antal sidor. I stället för att man manuellt måste klicka sig vidare mellan sidorna, så automatiserar programmet den processen.
Sjunde delen av Scrapingskolan är uppdelad i två avsnitt:
…men först var vi inte. (Tack Bertholof Brännström; tidningen finns på Strömbäcks folkhögskola.)
Ett år nådde sin ände och ett nytt passerade dörren. Det gamla fick byline och det nya rubrik. En ava följdes av en påa.
Under 2013 fick vi ur oss sådär 90 inlägg, och en återblick visar att vi åtminstone täckt in ett gäng sub-kategorier under ”journalistik” och ”teknik”.
Mycket webb har det förstås blivit, till exemel om hur man fiskar i framtiden – alltså automatiserar bevakningen av sina stories och ämnen – med hjälp av agenter och larm, och hur man kan göra avgränsningar som plockar bort skräp från svensk politik. (Till exempel alltså. Men oj vad vi var nöjda med den rubriken!)
Men årets i särklass största webbildningsinsats var förstås Elias’ Scrapingskola, som hittills tagit sig igenom inte mindre än sex lektioner (del 1, del 2, del 3, del 4, del 5 och del 6).
Programlederi i tv hade ingen av oss några större erfarenheter av – fram till att Elias under året intog Sydnytts morgonsändningar. Vilket han naturligtvis bloggade om i tre initierade poster (om förberedelserna, smygpremiären och premiären).
Redan 2012 hade vi dock kunnat erbjuda programledartips från svt-kollegan Lina Lindahl, och även 2013 kom gästbloggarna att skapa några av våra allra mest omtyckta och uppmärksammade poster.
Bo Torbjörn Ek skrev om ett klassiskt sätt att hitta hemliga handlingar, Jenny Berggren och Björn Wendelborn Barr om hur dejtingsajter kom till nytta när grävet sprängde landsgränserna, Jens Mikkelsen om granskningen där offentlighetsprincipen kunde användas på Facebookmeddelanden och Sofia Nordén om värdet av goda ansvarsintervjuer vid granskning av dysfunktionella torgtoaletter.
Researchern Jenny Küttim har jobbat med granskningar av Thomas Quick-fallet med både Hannes Råstam och Dan Josefsson. För oss skrev hon en mycket uppskattad checklista för research. På motsvarande sätt lärde Therese Bergstedt ut en rad lärdomar om vetenskapsjournalistikens fallgropar.
Frilansjournalisten och nätresearchvirtuosen Leo Wallentin har under året gett oss två spännande poster, den ena om försämrad offentlighet kring uppgifter om vem som registrerat en .se-adress (där vi via kommentarsfältet så småningom fick veta att försämringen inte blivit riktigt så omfattande som Leo varnade för) och den andra om hur man ska göra för att bedöma sajters storlek – inte. Med exempel från en statlig myndighets mindre lyckade (men mycket uppmärksammade) bedömning av extremistsajter. Myndighetskritik, mediekritik och webbresearchutbildning i ett med rätta uppmärksammat inlägg!
Årets mest populära gästblogg, räknat i antalet besökare här på bloggen, skrevs av granskande konsumentreportern och Plus-programledaren Åsa Avdic, och handlar om hur man lär sig känna igen och hantera falska pudlar. Posten nådde en sådan spridning att falskpudeln utnämndes till veckans nyord, och inlägget blev ett av våra allra mest lästa.
Novus-chefen Torbjörn Sjöström skrev en gästpost om hur man avgör legitimiteten i undersökningar, ett ämne som avhandlades i ett par poster i årets början (första här och andra här) med anledning av en uppmärksammad opinionsundersökning om Annie Lööfs fallande stöd. Många deltog i diskussionen (som också togs upp av Sveriges radios Medierna) men allt fick en snopen vändning när det visade sig att Expressen (som var måltavla för kritiken) helt enkelt skrivit fel om den statistiska säkerställningen av undersökningen (se uppdateringarna av posterna).
Om vi vågar oss på en förutsägelse om det kommande året (och många kommande år) så lär diskussionen om journalisters relation till statistik inte vara avgjord i och med detta (hej supervalåret!).
Sommarvikarierna ja. Glädjande rykten har nått oss om att flera av årets poster kom att göra nytta under årets allra varmaste månader bland medarbetarna med de minst säkra anställningsvillkoren. Förutom tipslistan ovan även våra sommarvänliga råd för egna nyheter och görbara granskningar. (Ni som hänger upp våra bloggposter på redaktionen – skicka oss gärna en bild så vi kan släppa tvivlet på att detta verkligen händer :-))
Vår egen intervjuskola började redan 2012 men den sammanfattande posten med konkreta exempel (och länkar bakåt till alla delarna) publicerades 2013.
För den som till vardags vill försöka hitta nyheter rekommenderas de 25 nyhetskällorna som inte är tingsrätten (och tja, även nödnyheter kan ju ha sitt värde), och för den som har svårt med strukturen på storyn kan ”manus först” vara en strategi att testa. Har man inte varit förutseende nog att göra ”manus först” så måste materialet struktureras senare i processen, och i så fall rekommenderar jag den här metoden.
Apropå ”manus först” så var min favoritläsning under året förstås Story Based Inquiry, en 88-sidors gratisbok som jag rekommenderat så ofta på och utanför bloggen att det nog kan ha gränsat till missionerande.
Om man har svårt att strukturera sin granskning kan man fundera på om man borde förstärka något av granskningens tre ben, eller om den kanske tittar åt fel håll, och om man ska göra en ansvarsintervju kan det vara bra att ta reda på argumenten först. Men om datorn man använder sen ska slängas, lämnas bort eller säljas så bör granskaren förstås se till att alla känsliga uppgifter försvinner på riktigt.
En annan inspirationskälla har faktiskt varit tv-programmet Arga doktorn, som hittade ett (i alla fall för mig) helt nytt sätt att komma runt ansvarigas ovilja att kommentera ”enskilda fall”.
Har dessa journalisttips inte varit dig tillräckliga? I så fall kanske du behöver andra sorters tips – och i så fall får jag väl avsluta med posten som handlar om hur du går till väga för att få väldigt många…tips.
Ett nytt avsnitt av Scrapingskolan är äntligen klart! Och det var verkligen på tiden!
I samband med en kurs på Fojo försvann prestationsångesten för att få ur mig ett nytt avsnitt. I stället byttes den ut mot inspiration – som är en mycket bättre drivkraft.
Det är så roligt att träffa människor som tittat in här och inse att människor faktiskt läser och har glädje av bloggen. Att föreläsaren avslöjade att han ägnat sin föräldraledighet åt att titta igenom Scrapingskolan var helt avgörande för att den här delen kommer just nu.
Här går vi igenom hur man använder Google Refine för att samla ihop information som finns på ett antal webbsidor vars adresser är konstruerade utifrån en speciell mall – till exempel genom en id-kod som finns listad på annan plats.
I bokens exempel handlar det om skolor vars id-nummer finns i Excel-fil på nätet. Den del i webbadressen som unikt identifierar varje skolsida är uppbyggd med hjälp av det speciella id-numret.
Kolla igenom i lugn och ro – och njut av det längsta avsnittet av Scrapingskolan så här långt! (Det är därför det är uppdelat i två delar.)
Särskilt du, Daniel Olsson – tack för inspirationen! Och kursansvarige, Per Nygren! Och alla klasskamrater!
Efter en tids uppehåll är nu äntligen den femte delen i Scrapingskolan här! Jag går igenom hur man använder kalkylbladet i Google Docs för att scrapa material från flera webbsidor samtidigt.
Hemligheten är att göra det i flera steg. I det första steget scrapar man ihop ett antal länkar. I det andra steget använder man sedan de länkarna som argument till ytterligare en importXML-funktion – som scrapar själva de data man var ute efter.
I och med denna del av Scrapingskolan lägger vi Google Docs bakom oss. I nästa avsnitt ska vi sätta tänderna i Google Refine i stället!
Här – äntligen – kommer nästa del i Scrapingskolan. Den här gången tittar vi lite mer på xpath-språket som man använder för att formulera sina sökfrågor mot de webbsidor man vill hämta hem sina data ifrån.
Är det något du vill få djupare eller annorlunda förklarat? Eller saknar du något? Kom gärna med kommentarer och inspel!